
Item analysis
‘How reliable is this test?’ If you’re about to choose a language test for your institution, you probably want to know the answer to that question. But what exactly does reliability mean? How is it measured? And how does it affect the way a test is created?
The first thing to say is that reliability is a statistical concept. Farhady (2012) gives this example to illustrate it: a student takes a test of 100 items and scores 40; two days later she takes the test again and scores 90; the teacher doubts the results, so the student takes the test again and scores 70. Anyone seeing these results would immediately recognise that the test was unreliable and wouldn’t use it (or let’s hope not). But don’t assume that the student would have got identical scores if they’d been taking a reputable test. In the real world, there will always be some variation – maybe the student was tired on one day, or the room was too hot to concentrate properly. The purpose of reliability analysis, therefore, is to measure the degree of consistency in test scores.
Item analysis is a key way to ensure the reliability of a test. Test providers gather data about every candidate’s performance on each individual item in the test. For a test like the Dynamic Placement Test, six months of test data can equate to hundreds of thousands of rows in a spreadsheet and therefore we can be sure that the results will be meaningful. There are three main measures of item performance: item facility, item discrimination and distractor distribution.
Item facility
Item facility simply measures the proportion of correct answers for each item – for example, if 72 out of 100 candidates answer it correctly, the item facility is 0.72. Imagine an item which every candidate, from A1 to C2, gets right. Or an item which everyone gets wrong. What is the value of these items? They don’t give us information about the relative ability of candidates. For a test like the Dynamic Placement Test, which assesses candidates across the full range of CEFR levels, it is important to have a wide and well-spaced range of facility values. Nevertheless, an item facility score that is too high or too low (typically above 0.7 or below 0.3) indicates that an item is not as useful as it should be.
Item discrimination
Item discrimination shows how well an item distinguishes between stronger and weaker candidates. In the Dynamic Placement Test, it is important that some items will only be answered correctly by, for example, candidates at B2 level or above. Item discrimination measures the correlation between the candidate’s score on a particular item and their score across the test as a whole. Item discrimination values will ideally fall between 0.25 and 1, and the closer to 1, the higher the level of discrimination. A value below 0.25 indicates that most candidates will get the same score on an item, regardless of their ability and is therefore not very useful.
Distractor distribution
One common type of question is the multiple-choice question, where candidates have to choose between a range of options (typically between 3-5). Incorrect options are often called ‘distractors’. If an item is performing badly on item facility or item discrimination, it is possible to analyse the choice of distractors. See this data for a poorly performing item:
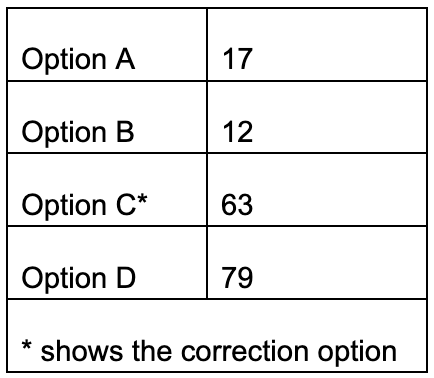
In this case, candidates chose one distractor (D) more often than the correct option (C), so the cause of the problem is likely to be in the way options C and D are written.
The beauty of item analysis is that it gives test creators objective data about the reliability of each item. First of all, you want to see that most of your items fall in the desirable zones (item facility: between 0.7 and 0.3; item discrimination above 0.25). This shows that your test is reliable. Secondly, if you know an item falls outside those zones, you can examine the reasons why it’s too easy or too difficult. Perhaps there’s ambiguity in the question; a distractor may be too attractive; the content may not be equally accessible to people from different cultural backgrounds. The editorial team can then rewrite the item and it can be re-tested, before being returned to the live test. Alternatively, the team may decide to drop the item altogether and write a new one. For example, there was one item in the pre-testing of the Dynamic Placement Test, which almost every candidate from A1 to C1 answered incorrectly:
Move the word to the right place in the sentence.
I personally think going to university is a good idea. [quite]
The team wasn’t sure exactly why the item had proved so difficult but it clearly wasn’t working, so they replaced it with a new one focusing on the same point. Analysis of the new item showed that its facility and discrimination were both good.
One final word… remember that reliability is not the same as validity (another word you’ll probably hear when people talk about tests). Validity is about showing that the test measures what it is supposed to measure – for example, does a university entry test actually show whether a student has the necessary abilities to perform well at university? The test could be highly reliable (i.e. its scores are very consistent) but it wouldn’t be valid if it only tested students’ knowledge of everyday vocabulary. Reliability is a necessary quality of a good test but it’s not the be-all and end-all. A good test must be both valid and reliable.
Reference
Farhady, H. (2012). Principles of Language Assessment. In Coombe, C. et al (Eds). The Cambridge guide to second language assessment (pp.37-46). Cambridge University Press.

